This paper describes the development of one such Turing System, including the technical design of the program and its performance on the first three Loebner Prize competitions. We also discuss the program's four year development effort, which has depended heavily on constant interaction with people on the Internet via Tinymuds (multiuser network communication servers that are a cross between role-playing games and computer forums like CompuServe).
Finally, we discuss the design of the Loebner competition itself, and address its usefulness in furthering the development of Artificial Intelligence.
In 1991, Dr. Hugh Loebner, the National Science Foundation, and the Sloan Foundation started the Loebner Prize Competition: an annual contest between computer programs to identify the most ``human'' programs, and eventually to award $100,000 to the program that first passes an unrestricted Turing test [Epstein 92]. This competition has been criticized as a parlor game, rewarding tricks rather than furthering the field of Artificial Intelligence [Shieber 92].
In this paper, we discuss our own entry in the Loebner competition, including a description of our own tricks, and describe how techniques and methods from AI are used to go beyond tricks. One of our goals is to encourage more participation by the AI community in the Loebner Competition.
ELIZA sparked the interest of many researchers, but perhaps the most interesting result was Colby's work on PARRY [Colby 75]. Criticism of ELIZA as a model for AI focused on the program's lack of an internal world model that influenced and tracked the conversation. PARRY simulates paranoid behavior by tracking its own internal emotional state on a few different dimensions. Colby subjected PARRY to blind tests with doctors questioning both the program and three human patients diagnosed as paranoid. Reviews of the transcripts by both psychiatrists and computer scientists showed that neither group did better than chance in distinguishing the computer from human patients.
Often overlooked is Colby's comparison of PARRY's and human dialogs with RANDOM-PARRY. He showed that just choosing responses at random did not model the human patients' responses as well as standard PARRY. Shieber argues that PARRY fooled its judges because paranoid behavior makes inappropriate responses or non sequiturs appropriate. But there is still a certain logic to them that PARRY simulates effectively. It is simpler to simulate paranoid behavior, perhaps, but it is not trivial.
In our view, PARRY is an advance over ELIZA because PARRY has a personality. The Rogerian therapist strives to eliminate all traces of his or her own personality, and ELIZA therefore succeeds without one.
TINYMUD provided a world filled with people who communicate by typing. This seemed to us to be a ripe opportunity for work on the Turing test, because it provided a large pool of potential judges and interviewees. In TINYMUD, computer controlled players are called ``bots'', short for robots. Many simple robots were created, and even ELIZA was connected to one stationary robot (if a player went alone into a certain cave, he could chat with ELIZA).
We created a computer controlled player, a ``Chatter Bot,'' that can converse with other players, explore the world, discover new paths through the various rooms, answer players' questions about navigation (providing shortest-path information on request), and answer questions about other players, rooms and objects. It can even join in a multi-player card game of ``Hearts'' It has won many rounds, ``shooting the moon'' on several occasions.
The conversational abilities were originally implemented as simple IF-THEN-ELSE rules, based on pattern matching with variable assignment. Most patterns have multiple outputs that are presented in a random, non-repeating sequence to handle users who repeat their questions.
A primary goal of this effort was to build a conversational agent that would answer questions, instead of ignoring them, and that would be able to maintain a sequence of appropriate responses, instead of relying on non-sequiturs. We included a lot of humor among the responses, and succeeded in making an agent more interesting than ELIZA; Wired magazine described our program as ``...a hockey-loving ex-librarian with an attitude.'' [Wired 93].
The CHATTERBOT succeeds in the TINYMUD world because it is an unsuspecting Turing test, meaning that the players assume everyone else playing is a person, and will give the CHATTERBOT the benefit of the doubt until it makes a major gaffe.
The competition was smaller in 1992 and 1993, down to three computer programs from six, and the same three programs have finished first, second, and third all three years. In 1992, we chose hockey as a domain for discourse, and the program finished dead last, partly because of a lack of hockey fans among the judges (leading to more difficult questions). The conversational model was expanded to include a tree-shaped network of input/output patterns, much like the opening book of a chess program, but the mismatch of expectation between the program and the judges was so great that very few conversations followed the expected lines of questioning.
For 1993, we chose a more universal topics, ``Pets,'' on the premise that everyone has had a pet at some time in their life. The tree-based model was scrapped in favor of an activation network that was less rigid and allowed the program to make more associations between the judge's input and its own output. Although the program still finished third of three, it was no longer dead last: two of eight judges ranked it more human than the second place program, and a third judge ranked it above the first place program.
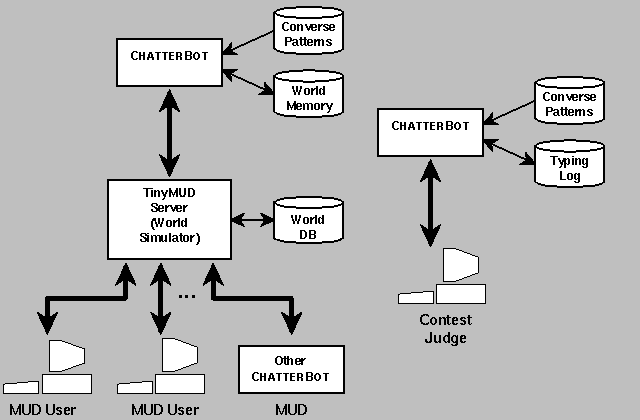
Figure 1: CHATTERBOT Configured for TINYMUD and for Loebner
The conversation module is implemented as a prioritized layer of mini-experts, each an ordered collection of input patterns coupled with a set of multiple possible responses.
<havepet>
a:1.0
p:1 *
r:Do you have any pets?
+:<havepet-1> <havepet-2> <havepet-3> <havepet-4> <havepet-5>
<havepet-6> <havepet-7> <havepet-8> <havepet-9>
<havepet-1>
a:0.1
p:1 NEG
r:Why not?
+:<havepet-1-1> <havepet-1-2>
-:<havepet-9> <id-46>
<havepet-1-1>
a:0.02
p:2 *apartment*
p:3 *allerg*
r:You could still have a fish tank, or maybe a terrarium with a
turtle or two.
-:<havepet-9>
Figure 2: Sample conversational nodes
Each node has 5 attributes:
Figure 3 shows a small portion of the pet domain network. Additional world knowledge is encoded in the ontology used during pattern matching. The program has a typical type hierarchy that allows a pattern to match just DOG, BIRD, PET, WILD, or ANIMAL, for example.
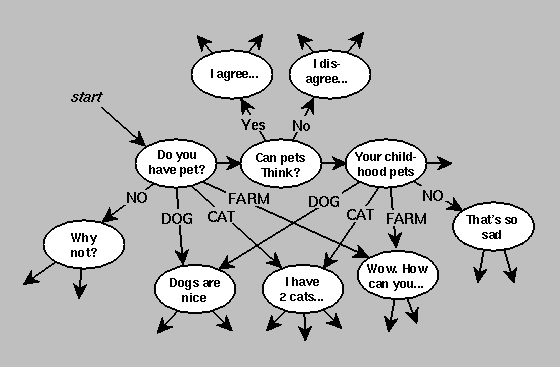
Figure 3: Portion of conversational network
Given a sufficiently large network of conversational nodes (our program ran with 224 nodes, plus 529 fixed responses), the conversation problem reduces to a retrieval problem: among the things that I could say, what should I say?
For example, if the user input mentions birds, the response strings are searched for matches to birds, including parrots, canaries, etc., and those nodes have their activation level raised. The code was borrowed from one of our information retrieval engines.
By encoding information about the user in the activation levels, the program tracks the judge's responses. For example, if the judge answers negatively to the question about whether he has pets, the other nodes that ask about pets are inhibited.
Here we unashamedly describe some of the better tricks, confident in the belief that when someday a computer program does pass the Turing test, it will use many of them, for the simple reason that people already use them everyday.
What I had not realized is that extremely short exposures to a relatively simple computer program could induce powerful delusional thinking in quite normal people.
The illusion of listening is fostered by including substrings of the user's input in the program's output
User: You hate me.
Eliza: Does it please you to believe that I hate you?
A further trick is the use of the Rogerian mode, which provides
unimpeachable cover for the computer. Since the program never says anything
declaratively, it cannot contradict itself later.
Judge: Do you know anything about miniature schnauzers?
ChBot: I don't know anything about miniature schnauzers, Judge.
Admitting Ignorance, repeating user input
Judge: Well, I have one. We call him Pucci. He is a crazy cat--
have you ever had a cat?
ChBot: What a coincidence! I have two cats
direct answer to direct question from activation net
Judge: I prefer dogs myself. Cats are too independent and they
always jump up on things. By the way, are you a hep cat?
ChBot: People don't own cats...it's the other way around.
controversial statement with expected followups
Judge: Some people have snakes for pets-- do you think they can
be of any value as a pet?
ChBot: I think cat people are very self-assured. Cats are very
independent, but they can also be very loving. Dogs are
just too subservient and quick to please for my taste.
rigidly following up on previous statement about cats independence,
but reference to snakes increases activation of snake topic.
Judge: Okay-- but how do you "pet" a snake?
ChBot: Wow, that's unusual. I don't know many snake owners.
snake topic activated after two references
Judge: How about turtles? All they do is sit in their little
artificial ponds, eat and shit, am I right?
ChBot: Turtles just aren't very satisfying as pets. They don't
seem to have emotions.
direct response from activation network
Judge: Aha! But where do we draw the line as humans? Who are
we to decide which animals have worth and which do not?
ChBot: Go on.
default, non-committal response, given no hot topic keywords
Judge: Take bees for example. I happen to like them.
ChBot: Me too.
TINYMUD level lo-priority response to user's liking something
By our rough estimate, 7 of these 8 replies are responsive, although the last 2 are somewhat weak. The ``self-assured'' reply we judge unresponsive. A similar analysis of the entire 3 hour log showed that only 45 of the 137 (34%) replies were responsive, so the average performance was not as good as this particular dialog. We also found another 34 cases (25%) where the activation network did contain a responsive reply that could have been used if the input patterns were more complete.
The basic method is to use a Markov model of the intercharacter delay based on character trigrams. We obtained the real-time logs of the 1991 competition from the Cambridge Center for Behavioral Studies, and sampled the typing record of judge #10 (chosen because he was the slowest typist of all 10 judges). The average delay between two characters is 330 milliseconds, with a standard deviation of 490 milliseconds (these values were computed from a total of 9,183 characters typed by that judge during a three hour period). We also determined that it took the judge an average 12.4 seconds with a standard deviation of 11.4 seconds to begin typing after seeing the terminal output.
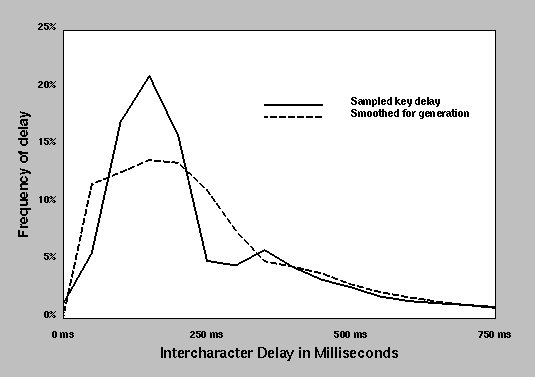
Figure 4: Judge #10: Intercharacter delay distribution
Trigram Count Seconds Trigram Count Seconds
< t,pn, s> 7 0.11 +- 0.04 <sp,sp,up> 16 1.06 +- 1.25
< r,bs,bs> 8 0.15 +- 0.03 <up,up,bs> 12 1.16 +- 0.72
<sp, i, s> 37 0.16 +- 0.10 < e,sp, w> 11 1.24 +- 2.68
< e,bs,bs> 9 0.17 +- 0.03 <bs,bs,up> 19 1.33 +- 1.40
< u, l, d> 13 0.17 +- 0.07 < e,sp,up> 6 1.34 +- 0.97
< i, n, g> 35 0.17 +- 0.10 < o, n,pn> 13 1.38 +- 1.15
<bs,bs,bs> 187 0.18 +- 0.30 <up,sp,bs> 6 1.53 +- 1.50
< n, o, w> 22 0.19 +- 0.12 <pn,sp,up> 16 1.57 +- 2.94
<up,bs,bs> 9 0.19 +- 0.06 < e, r,pn> 7 1.99 +- 2.28
< u, e, s> 7 0.21 +- 0.04 < a,sp, s> 8 2.29 +- 4.14
Fast Trigrams Slow Trigrams
Figure 5: Judge #10: Outlier trigram statistics
After the response has been generated by the conversational components, the typing simulator inserts random errors (1 in 68 characters), such as mishits, transpositions, insertions and deletions, and case errors. A physical model of key positions on the standard QWERTY keyboard is used to generate mishits. After the error is inserted, backspaces and the correct letters are inserted to simulate backing up to correct the error (5% of mistakes are left uncorrected). All of these probabilities were estimated by analyzing the log of judge #10.
Once the errorful string with corrections is generated, it is displayed to the judge one character at a time with random delays between the characters. The delay times are generated by using the smoothed probability distribution shown in Figure 4, with the mean and standard deviation modified to match the trigram statistics shown in Figure 5. For trigrams with 3 or fewer occurrences in the input log, bigram or single character statistics are used.
Judge: Have you ever kept a penthouse pet?
ChBot: Do you have any pets?
Judge: I think you're avoiding my question.
ChBot: Do you think that animals can think?
Judge: Do you think it ethical for one species to enslave another?
ChBot: What kinds of pets did you have as a child?
Judge: I'm asking the questions. What is a pet if it is not a slave
of species-ism?
ChBot: Oh, that's so sad. I think pets enrich a childhood immensely.
Judge: How can we keep some animals as pets, yet eat others?
ChBot: Guinea pigs are about as smart as cucumbers.
We don't believe that the restriction to a domain weakens the test in
any important way. If a program can pass the test in a single domain,
then 50 or 100 groups making similar programs for different domains
would make a program broad enough that the judge and the program could
find common ground for a discussion. By taking the initiative, the
program could lead the judge into an area of its own expertise. Note
that ELIZA didn't restrict its users to a single domain.
Another unforeseen difficulty faced by our program in 1993 was that each judge was given two turns, instead of one turn as in the first two competitions. We had just weeks before installed code to detect a change of judges based on the timing of the input. When a new judge was detected, the activation levels of the nodes were reset so that each judge started out with a fresh network. This greatly improves the coherence of the dialog for each judge, but it meant that during their second conversations most of the judges had one or more responses repeated. Some even commmented on it during the test:
Judge: What is your favorite dog breed?
ChBot: We had to bgive her away. We only had a fifth of an
acre of land, and aussies love to run.
Judge: You're giving me the exact same answers you gave me first
time around. What is your favorite dog breed?
In effect, this change in the methodology turns what had been a 15 minute test into a 3 hour long test, making it much more difficult for the program. Turing's original game was only 5 minutes long. Indeed, by asking the judges' final rankings after they've had 3 hours of interaction with a collection of people and computers, they may have learned enough about computers to no longer qualify as average questioners. The scores would probably be quite different if each judge spent only 5 minutes with each program.
But suppose that simply increasing the size of ELIZA's script or the CHATTERBOT's activation net could achieve Turing's prediction of fooling 70% of average questioners 5 minutes. After all, the CHATTERBOT has already fools ``average'' questioners in the TINYMUD domain for a few minutes. If a larger collection of ``tricks'' sufficed, would you redefine ``artificial intelligence,'' ``average questioner,'' or ``trick?''
We would like to see increased participation in the Loebner Prize. We hope by dissecting one of the three best programs in the competition to spur others to conclude ``I could have written something better than that!'' and then do so.
Information about the Loebner Prize Competition may be obtained from Cambridge Center for Behavioral Studies, 675 Massachusetts Avenue, Cambridge, Mass., 02139.